Anthropic《Measuring AI Agent Autonomy in Practice》分析
Anthropic研究
方法论
Claude Code
998,481
工具调用样本数
500,000
Claude Code会话样本
99.0%
风险评估准确率
97.5%
停止原因分类准确率
一、研究方法论详解
Anthropic在《Measuring AI Agent Autonomy in Practice》附录中详细披露了其研究方法论。这份29页的附录文档揭示了如何对近百万次Agent交互进行系统性分析,为理解Agent行为提供了严谨的框架。
1.1 数据采样策略
研究团队在2026年1月19日至2月2日期间(UTC时区),从公共API中随机抽取了998,481次工具调用,同时从Claude Code中抽取了各50万次的中断、用户提问和会话数据。采样排除了零日保留策略客户以及不允许聚合分析的使用者。
1.2 分类模型与提示词设计
研究使用claude-sonnet-4-5-20250929模型(温度0.2,最大思考长度1024 tokens)对所有样本进行复合分类。分类维度极其丰富,涵盖15个核心维度:
| 维度类别 | 具体维度 | 说明 |
|---|---|---|
| 行动分析 | Action, Goal, Goal Complexity | 理解Agent在做什么 |
| 环境分析 | Environment, Environment Type, Environmental Impact | Agent操作的系统类型 |
| 自主性分析 | Human in Loop, Autonomy (1-10) | 人类监督程度 |
| 风险分析 | Reversibility, Risk (1-10), Safeguards | 行动的潜在影响 |
| 架构分析 | Agentic Architecture | 单Agent vs 多Agent |
二、验证方法与准确率
2.1 各维度准确率
| 维度 | 准确率 | 备注 |
|---|---|---|
| Risk (1-10) | 99.0% | 与评估者评分±1范围内 |
| Autonomy (1-10) | 99.0% | 与评估者评分±1范围内 |
| Goal Domain | 99.0% | 样本偏向软件工程 |
| Reversibility | 100% | 分布集中在"不适用"和"易逆转" |
| Safeguards Present | 90.5% | 倾向于识别存在而非缺失 |
| Human in Loop | 77.5% | 不对称错误 |
| Goal Complexity | 88.0% | 高复杂度任务分类不稳定 |
| Stop Reason | 97.5% | Claude Code停止原因 |
人类在环分类的不对称性
当Claude判断"无人类参与"时,100%正确;当判断"有人类参与"时,仅46%正确。这种"过度归因人类参与"的偏差意味着报告中的人类参与率(73%)可能是上限估计。
三、核心图表解读
3.1 Claude Code单轮时长分布
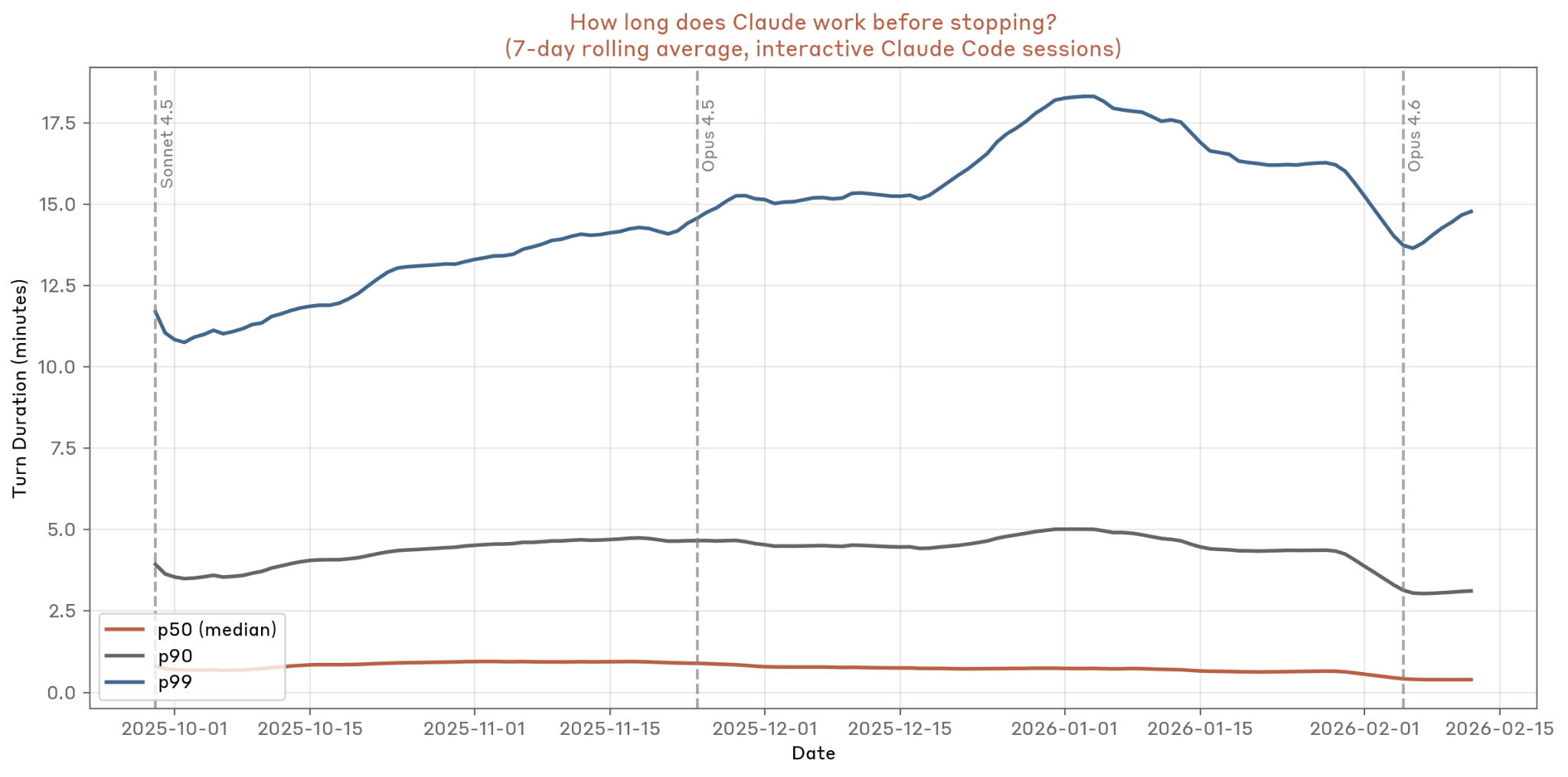
Figure A1: 中位数、90%分位和99%分位单轮时长(2025.10-2026.01)
关键发现:99%分位时长从约10分钟增长到约18分钟,表明最长任务的持续时间在显著增长。增长的平滑性(跨越多个模型版本)表明这不是模型能力跳跃的结果,而是用户信任积累和任务复杂度提升的综合效应。
3.2 极端时长(99.99%分位)
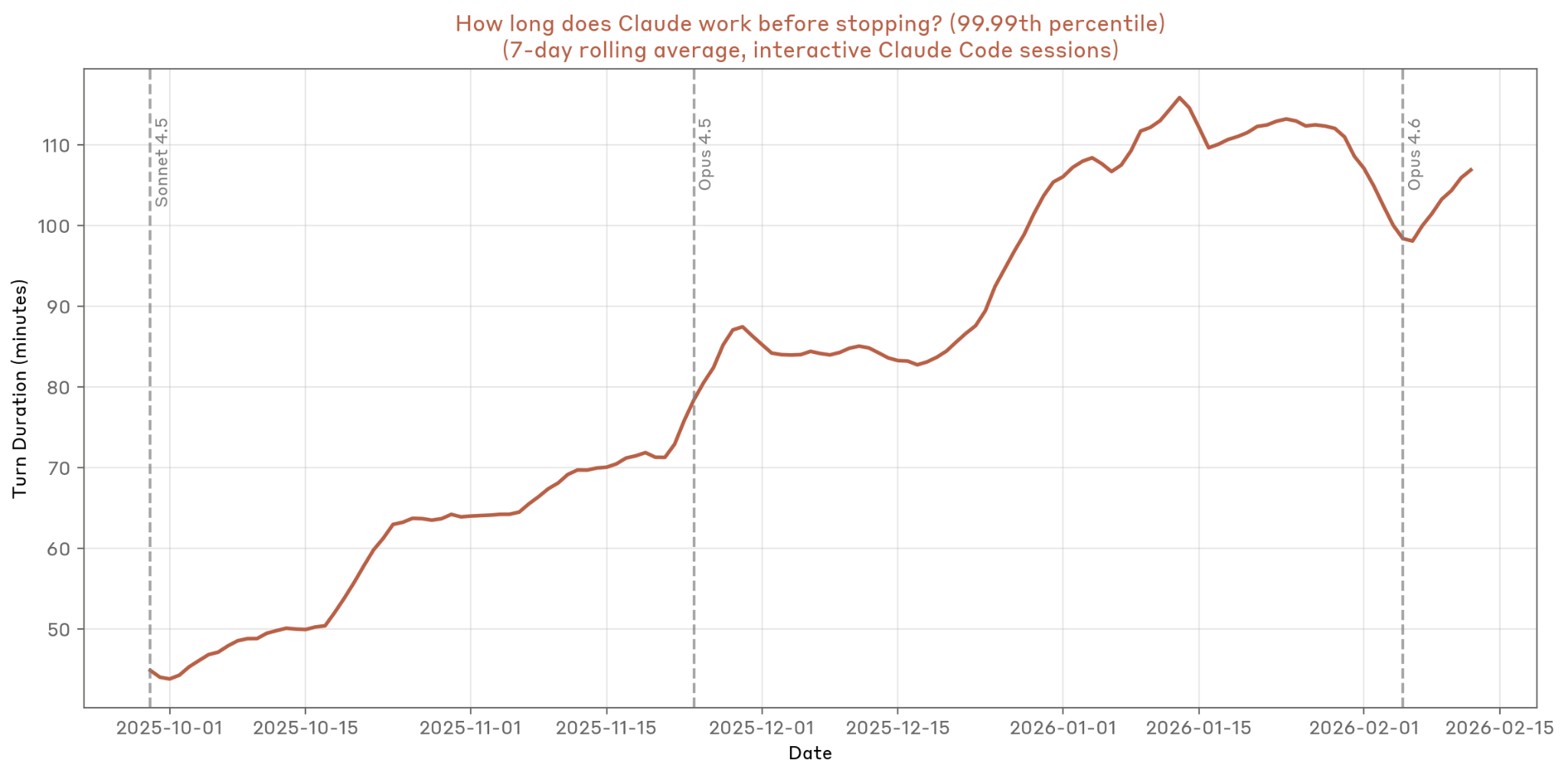
Figure A2: 99.99%分位单轮时长(极端长任务)
关键发现:99.99%分位时长从25分钟增长到45分钟以上,代表最极端的自主运行场景——Claude连续工作近1小时无需人类干预。
四、Claude Code停止原因分析
| 为什么Claude停止自己 | 为什么人类中断Claude |
|---|---|
| 呈现选项供用户选择 (35%) | 提供缺失的技术背景或修正 (32%) |
| 收集诊断信息或测试结果 (21%) | Claude太慢、卡顿或过于冗长 (17%) |
| 澄清模糊或不完整的请求 (13%) | 已获得足够帮助可自行继续 (7%) |
| 请求缺失的凭证、令牌或访问权限 (12%) | 想自己进行下一步(如手动测试、部署、提交)(7%) |
| 获取批准或确认后再行动 (11%) | 中途改变需求 (5%) |
核心洞察
在复杂任务中,Claude主动暂停请求澄清的频率是用户中断的2倍以上。这意味着Agent对实时性要求更高——它需要快速获得人类反馈才能继续执行。